Software profesionálů
Reálné prodejní ceny
přímo do posudku
- V databázi 2 500 000 objektů najdete určitě vhodnou srovnatelnou nemovitost
- Umíte nalézt skutečně reprezentativní objekt?
- Matematický model MoniT Vám pomůže vyhledat nemovitosti, které odpovídají cenou i kvalitou.
- Je Váš posudek skutečně nenapadnutelný?
- Umíme pro Vás vyhledat reálnou prodejní cenu z katastru a spárovat ji s realitní nabídkou, takže bude mít skutečnou cenu i podrobný popis nemovitosti.
Přehledné uživatelské prostředí
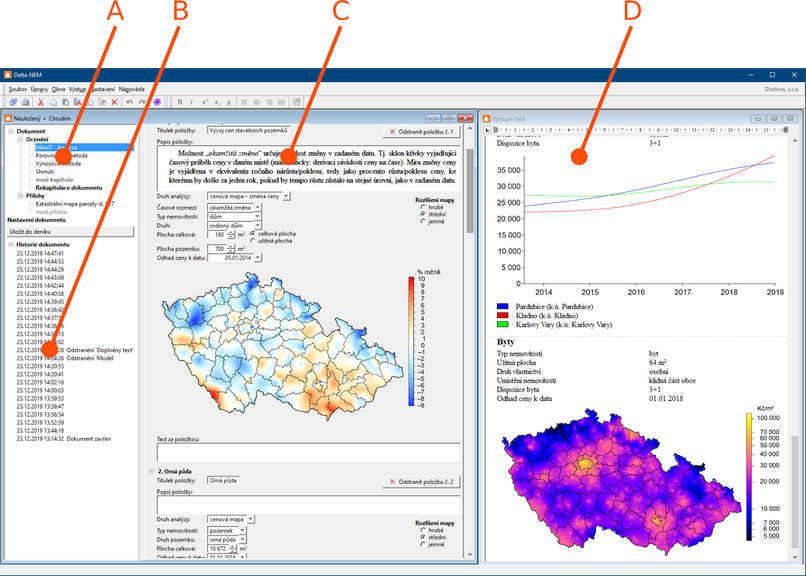
A – seznam kapitol dokumentu. Ať už jde o znalecký posudek, odborný odhad nebo analýzu trhu, dokument je přehledně členěn na kapitoly. Při ocenění podle vyhlášky je struktura kapitol daná. Pro tržní oceňování má uživatel volnost zvolit strukturu kapitol tak, aby odpovídala jeho záměrům. Každá kapitola odpovídá jedné metodě ocenění resp. ocenění jedné součásti nemovitosti.
B – historie dokumentu. Při úpravách se dokument automaticky ukládá. Zde je zobrazena historie úprav. Je možné zobrazit starší verzi dokumentu a případně se k ní vrátit, pokud byly omylem provedny nechtěné změny.
C – data aktuální kapitoly. Podle zvoleného typu kapitoly (který odpovídá určitému oceňovacímu postupu) jsou zde zobrazeny datové položky, které je třeba zadat. V průběhu zadávání dat program automaticky přepočívátá výsledek a zobrazuje všechny důležité mezivýsledky.
D – výsledný text kapitoly. Každé kapitole odpovídá výsledný text. Ten je možné nechat průběžně zobrazovat. Každá změna v datech ocenění se okamžitě promítne do výsledného textu. Uživatel tak má naprostou kontrolu nad výsledkem své práce.
Více v uživatelské příručce: Okno dokumentu
Podporované metody ocenění
- Vyhláška o cenách nemovitostí: od vyhl. č. 178/1994 Sb. po současnost
- Porovnávací metoda, napojení na databázi a model MoniT
- Reprodukční ceny, napojení na databázi agregovaných rozpočtových položek THU RTS
- Výnosová metoda
- Obvyklé nájemné pomocí reverzní výnosové metody
- ...a další
Systém kapitol –
volné členění posudku
- Nediktujeme znalci, jak má jeho posudek vypadat
- Rozčleňte svůj posudek tak, jak to odpovídá povaze ocenění
- Několik alternativních metod ocenění
- Ocenění ke dvěma různým datům
- Vyhláška a tržní ocenění v jednom posudku
- Areál ve více katastrech
- Seskupení objektů podle funkční logiky
Úložiště dokumentů –
automatická správa posudků
- Program se sám stará o přiřazení čísla posudku
- Seznam posudků podle let se souhrnnými informacemi
- Napojení na znalecký deník
- Zámek na dokončených posudcích brání nechtěné změně
Pohodlná práce
- Zobrazte si výsledný posudek již během zadávání dat, budete ho mít stále pod kontrolou
- Historie dokumentu – když si něco náhodou smažete, můžete to kdykoli vrátit zpět
- Přímé napojení na katastr – LV, seznam vlastníků, seznam parcel, katastrální mapy
- Pohodlný kalkulátor výměr
- Kdykoli práci přerušíte, program se po opětovném spuštění vrátí přesně tam, kde jste skončili